Launch Week, Day 3 - Consistency, Performance, and Multi-Region Availability


Happy hump day! Day 3 of launch week is focused entirely on some exciting performance and reliability upgrades for Warrant. In case you missed the previous days, here are the links: Day 1 and Day 2.
From the beginning, we've envisioned Warrant as a globally distributed, highly performant and highly available authorization service that developers can easily plug into their applications without worry. Building such a cloud service is tough. We're thankful to our customers who have entrusted us with powering their authorization and helped us evolve Warrant over the past year+ into a service that now processes millions of API requests per day while maintaining 99.995% availability (or < 30m of downtime per year).
Today, we're excited to talk about a few of the improvements we've made over the past several months that have helped us get here:
Data consistency
First, a note about data consistency. Writes within Warrant have always been atomic, with each write (API call) committing within an independent transaction. Over the past few months, we've overhauled the core service to store and expose 'Warrant-Tokens' on writes, similar to Zanzibar's zookies (fun fact - we call these tokens 'wookies' internally). These tokens represent transactions and together maintain a linear timeline of writes taking place within a customer environment. You can read more about 'Warrant-Tokens' here.

Chewie is a proponent of user-specified data consistency
In addition to exposing 'Warrant-Tokens' on writes, reads now accept client-passed 'Warrant-Tokens' as well. Passing a token on a read operation instructs the server to process the request on data no older than the transaction specified by the passed in 'Warrant-Token'. This gives flexibility to both client and server: clients have the ability to 'select' their desired consistency level on a per request basis and the server can maintain and use cached data that is bounded by these consistency tokens.
In practice, these tokens work well to improve overall performance while maintaining consistency guarantees. For example, let's say that you make 3 writes in a row: (1) assign permission:create-report to role:admin, (2) assign permission:read-report to role:admin, and (3) assign role:admin to user:beth. Each of these writes generates a new 'Warrant-Token': token1, token2, and token3 respectively. If you immediately make a check request to check whether user:beth can permission:create-reports (via role:admin) using token1, you may or may not get true. However, if you call check with token3, you are guaranteed to get a true result, given that the server must take the 3rd write into account, even if the result is not cached.
The addition of 'Warrant-Tokens' gives Warrant the performance benefits of an 'eventually consistent' service (on a large majority of reads) while maintaining consistency guarantees as needed by the client (important for an authz service).
Performance
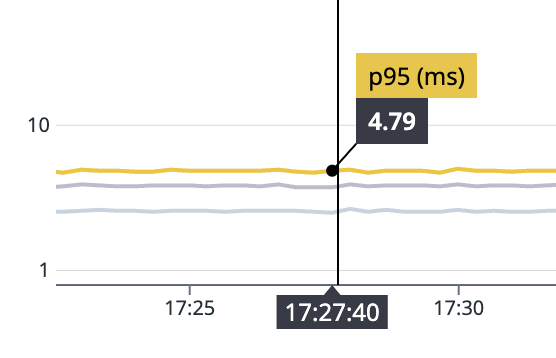
Enabling this 'client-specified' consistency via the 'Warrant-Token' has helped us unlock considerable performance improvements server-side, especially on our most trafficked endpoints: check and query. The server now caches various 'check' and 'query' results, including sub-checks and sub-queries (similar to the approaches mentioned in the Zanzibar paper), allowing a major chunk of requests to be served from cache while maintaining consistency guarantees to clients as needed.
In over 3 months of production deployment, we've observed check API p95 server latency of less than 5 milliseconds for most customers. This means end-to-end, in-region response times of ~25-30ms. Of course, these times also depend on access model complexity, but the results thus far have been great.
Multi-region availability
Speaking of regions, we're also excited to announce that Warrant is now online in even more AWS cloud regions within the United States. This enables us to run application servers in more locations, closer to our customers' applications. More importantly, these clusters also serve as failover clusters in case any region goes down.
That's it for day 3! We hope you're as excited about these performance and reliability improvements as we are! Join us back here tomorrow for day 4, and be sure to join us on Slack to talk shop, give us your feedback, or tell us what you'd like to see us work on next!